| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- lg인적성모의고사
- LG디스플레이
- sk
- lg합격
- lg적성검사
- 데이터분석
- cloudarchitecting
- 2022awscloudbootcamp
- awscloud
- aws
- lg디스플레이산학장학생
- lg인성검사
- LG인적성
- LGD
- 2022awscloud
- awscloudbootcamp
- awsacademy
- cloudfoundations
- lg인재상
- SKT
- SK인턴
- LG인적성후기
- sktai
- lg인적성합격
- e1인턴
- lg디스플레이lgenius
- lgenius
- DT
- aws클라우드부트캠프
- SKC&C
- Today
- Total
냥냥파워
ViT for Image Classification (Visual Transformer) 본문
https://github.com/FrancescoSaverioZuppichini/ViT
GitHub - FrancescoSaverioZuppichini/ViT: Implementing Vi(sion)T(transformer)
Implementing Vi(sion)T(transformer). Contribute to FrancescoSaverioZuppichini/ViT development by creating an account on GitHub.
github.com
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
https://viso.ai/deep-learning/vision-transformer-vit/
Vision Transformers (ViT) in Image Recognition - 2022 Guide - viso.ai
Vision Transformers (ViT) brought recent breakthroughs in Computer Vision achieving state-of-the-art accuracy with better efficiency.
viso.ai
Recently, Vision Transformers (ViT) have achieved highly competitive performance in benchmarks for several computer vision applications, such as image classification, object detection, and semantic image segmentation.
https://github.com/google-research/vision_transformer
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
The ViT models were pre-trained on the ImageNet and ImageNet-21k datasets.
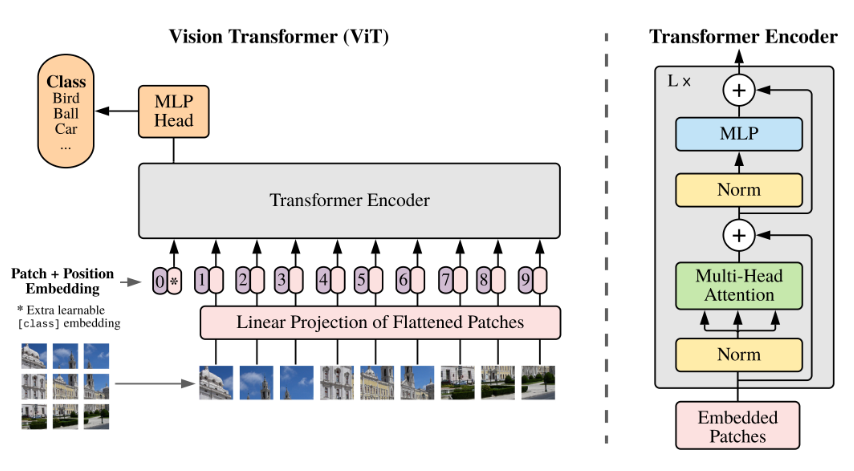
- Split an image into patches (fixed sizes)
- Flatten the image patches
- Create lower-dimensional linear embeddings from these flattened image patches
- Include positional embeddings
- Feed the sequence as an input to a state-of-the-art transformer encoder
- Pre-train the ViT model with image labels, which is then fully supervised on a big dataset
- Fine-tune on the downstream dataset for image classification